Studi Kasus Data Science Harga Minyak Dunia
Source Dataset: Oil Prices
Data Preparation
Dataset: Brent Crude Oil Prices dari https://github.com/datasets/oil-prices berisi data historis harian harga minyak Brent sejak tahun 1987. Dataset ini digunakan untuk analisis tren harga, evaluasi pasar, serta pemodelan time series dalam sektor energi dan ekonomi global.
Struktur Dataset
- Date: tanggal pengambilan data (format: YYYY-MM-DD)
- Price: harga Brent crude oil dalam USD
Langkah Persiapan
- Import pustaka pandas dan baca dataset dari URL
- Konversi kolom
Datemenjadi datetime untuk analisis waktu - Jadikan kolom
Datesebagai index - Gunakan
dropna()untuk menghapus data kosong
# Contoh kode lengkap
import pandas as pd
# 1. Membaca dataset dari URL
df = pd.read_csv("https://raw.githubusercontent.com/datasets/oil-prices/master/data/brent-daily.csv")
# 2. Konversi kolom Date ke format datetime
df['Date'] = pd.to_datetime(df['Date'])
# 3. Set kolom Date sebagai index
df = df.set_index('Date')
# 4. Hapus data kosong (jika ada)
df = df.dropna()
# 5. Lihat informasi struktur data
df.info()
# 6. Cek missing value
df.isnull().sum()
# 7. Statistik deskriptif dasar
df.describe()
# 8. Reset index jika diperlukan (mengembalikan kolom Date)
df.reset_index(inplace=True)
df.head()Penjelasan Fungsi
read_csv(): Membaca file CSV dari URL dan menyimpannya sebagai DataFrame.to_datetime(): Mengonversi kolom string menjadi objek datetime agar dapat digunakan untuk analisis waktu.set_index(): Mengatur kolom tertentu sebagai index, penting untuk time series.dropna(): Menghapus baris yang memiliki nilai kosong untuk menjaga kualitas analisis.info(): Menampilkan jumlah kolom, baris, tipe data, dan memori yang digunakan.describe(): Menyediakan statistik deskriptif untuk kolom numerik.reset_index(): Mengembalikan index menjadi kolom biasa untuk fleksibilitas analisis.
Latihan Teknis
- Jalankan
df.info()dan jelaskan apa yang Anda pahami dari hasil tersebut. - Gunakan
df.isnull().sum()untuk mengidentifikasi apakah ada kolom kosong. - Gunakan
df.describe()untuk memahami nilai minimum, maksimum, dan rata-rata harga minyak. - Reset index dan amati bagaimana struktur DataFrame berubah.
- Ubah URL dataset menjadi file lokal atau dataset serupa lainnya, lalu ulangi langkah di atas.
Dokumentasi Resmi:
Pandas Official Documentation
Exploratory Data Analysis (EDA)
EDA bertujuan untuk mengeksplorasi data agar kita memahami lebih jauh pola distribusi, outlier, tren musiman, serta potensi korelasi antar variabel. Tahap ini penting sebelum membangun model machine learning.
Tujuan EDA:
- Mengetahui ringkasan statistik deskriptif dari data
- Melihat tren dan pola musiman
- Mendeteksi outlier atau data ekstrem
- Memvisualisasikan hubungan antar fitur
Kode Contoh
# Ringkasan statistik deskriptif
print(df.describe())
# Lineplot tren harga minyak
import matplotlib.pyplot as plt
plt.figure(figsize=(12,5))
df['Price'].plot(title='Harga Minyak Harian')
plt.xlabel('Tanggal')
plt.ylabel('Harga (USD)')
plt.grid(True)
plt.show()
# Boxplot untuk mendeteksi outlier
plt.figure(figsize=(6,4))
df.boxplot(column='Price')
plt.title('Boxplot Harga Minyak')
plt.ylabel('Harga (USD)')
plt.show()
# Histogram distribusi harga
df['Price'].hist(bins=30, figsize=(8,5))
plt.title('Distribusi Harga Minyak')
plt.xlabel('Harga (USD)')
plt.ylabel('Frekuensi')
plt.grid(True)
plt.show()
# Deteksi tanggal harga tertinggi dan terendah
tanggal_max = df['Price'].idxmax()
tanggal_min = df['Price'].idxmin()
harga_max = df['Price'].max()
harga_min = df['Price'].min()
print(f"Harga tertinggi: {harga_max:.2f} USD pada {tanggal_max.date()}")
print(f"Harga terendah: {harga_min:.2f} USD pada {tanggal_min.date()}")Penjelasan Visualisasi:
describe(): memberikan statistik dasar seperti mean, median, std, min, dan max.- Lineplot: sangat bagus untuk mendeteksi tren jangka panjang atau pola musiman seperti kenaikan musiman atau efek krisis global.
- Boxplot: menunjukkan sebaran data dan nilai-nilai outlier, yang penting untuk evaluasi stabilitas pasar.
- Histogram: menggambarkan distribusi harga secara keseluruhan, membantu mengenali apakah distribusi simetris atau miring.
- idxmax() / idxmin(): mengidentifikasi tanggal ekstrim (harga tertinggi/terendah), bisa dikaitkan dengan peristiwa dunia nyata.

Latihan Teknis
- Tampilkan
df.describe()dan tentukan nilai rata-rata dan simpangan baku harga minyak. - Buat lineplot, boxplot, dan histogram untuk
Price. - Identifikasi tanggal dengan harga tertinggi dan terendah menggunakan
idxmax()danidxmin(), lalu bandingkan dengan peristiwa geopolitik yang mungkin berpengaruh. - Uji visualisasi untuk rentang waktu tertentu saja (misalnya 2008-2010) menggunakan slicing
df['2008':'2010'].
Referensi Dokumentasi: Pandas | Matplotlib
Feature Engineering
Feature engineering adalah proses penting dalam data science yang bertujuan menciptakan fitur baru dari data mentah untuk membantu model machine learning mengenali pola yang tersembunyi. Pada data deret waktu seperti harga minyak, teknik ini sangat berguna untuk mengungkapkan tren, pola musiman (seasonality), dan dinamika harga historis.
Contoh Kode Lengkap
# Muat data dan tangani nilai kosong
import pandas as pd
url = "https://raw.githubusercontent.com/datasets/oil-prices/master/data/brent-daily.csv"
df = pd.read_csv(url)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
# Tangani nilai null untuk kolom numerik (Price)
df['Price'] = df['Price'].fillna(df['Price'].mean()) # Imputasi dengan rata-rata
# Tambahkan kolom dengan nilai string yang null untuk contoh (misalnya 'Status')
df['Status'] = ['Aktif' if i%2==0 else None for i in range(len(df))] # Contoh string dengan nilai null
df['Status'] = df['Status'].fillna('Tidak diketahui') # Imputasi string
# Tambahkan fitur waktu
df['Year'] = df.index.year
df['Month'] = df.index.month
df['DayOfWeek'] = df.index.dayofweek
# Tambahkan rata-rata bergulir (Moving Average)
df['Rolling7'] = df['Price'].rolling(7).mean()
df['Rolling30'] = df['Price'].rolling(30).mean()Penjelasan Teori & Alasan
- fillna(): digunakan untuk mengisi nilai kosong. Untuk data numerik seperti harga minyak, kita bisa menggunakan rata-rata (mean), median, atau interpolasi. Untuk data kategori/string, kita bisa isi dengan label seperti "Tidak diketahui" atau modus.
- Ekstraksi waktu: Year, Month, dan DayOfWeek membantu mengidentifikasi pengaruh musiman terhadap harga minyak.
- Moving Average: Meratakan fluktuasi harga harian sehingga tren harga lebih mudah terlihat.
Visualisasi Tren Harga & Fitur
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
df['Price'].plot(label='Harga Harian', alpha=0.5)
df['Rolling7'].plot(label='Rata-rata 7 Hari', linewidth=2)
df['Rolling30'].plot(label='Rata-rata 30 Hari', linewidth=2)
plt.title('Harga Minyak & Moving Average')
plt.xlabel('Tanggal')
plt.ylabel('Harga (USD)')
plt.legend()
plt.grid(True)
plt.show()Ilustrasi
Moving Average membantu mengenali tren seperti:
- Kenaikan stabil harga (bullish trend)
- Penurunan berkelanjutan (bearish trend)
- Perpotongan antar MA (death cross/golden cross)
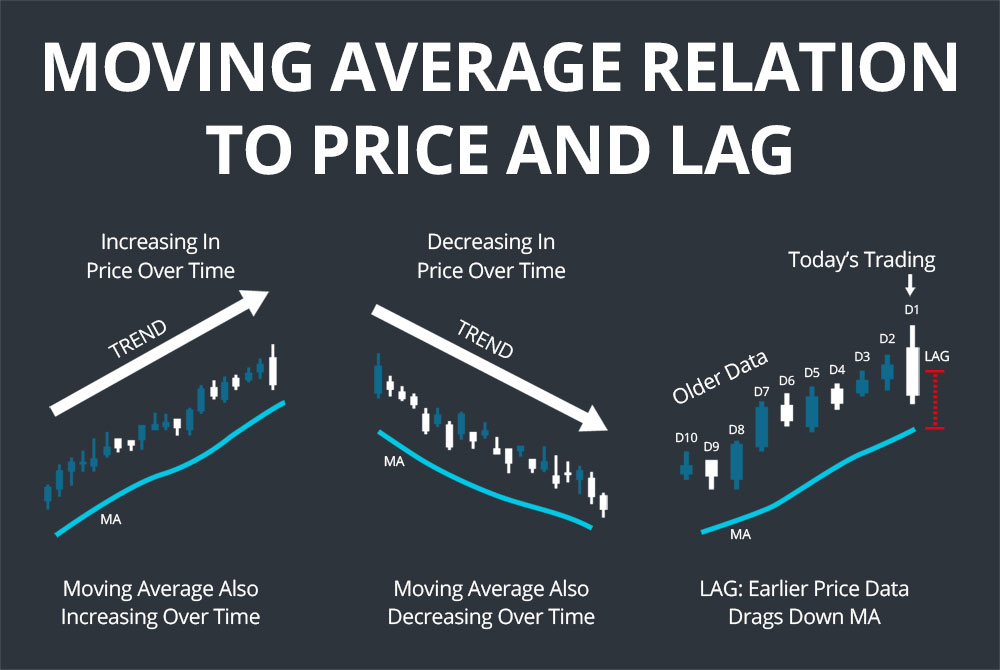
Latihan Teknis
- Tambahkan fitur
WeekOfYeardanQuarterdari indeks tanggal. - Buat fitur baru
Rolling90dan bandingkan visualnya denganRolling30. - Gunakan
groupby('Month')untuk menghitung rata-rata harga bulanan, lalu tampilkan grafiknya. - Hitung korelasi antara
Rolling30danPricemenggunakandf.corr()dan interpretasikan nilainya. - Buat kolom string
PeriodeberdasarkanYeardengan format 'Q1-2023' dsb dan analisis agregasi berdasarkan itu.
Referensi: Pandas, Matplotlib
Model Training
Jenis-Jenis Model Machine Learning
- Klasifikasi: Target adalah label diskrit, misal: spam/tidak.
- Regresi: Target berupa angka kontinu, seperti harga atau suhu.
- Clustering: Mengelompokkan data tanpa label, seperti segmen pelanggan.
Ilustrasi Model
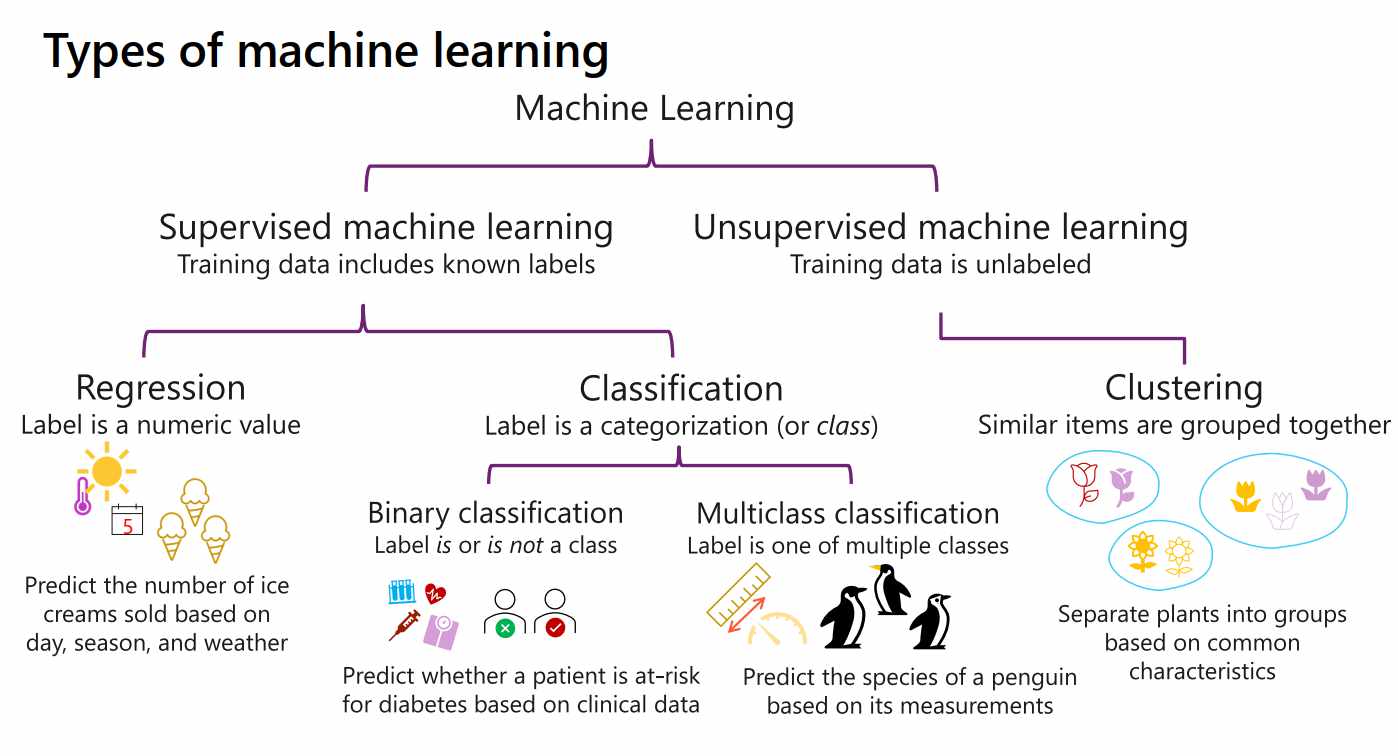
Pada tahap ini, kita akan melatih model prediksi menggunakan teknik regresi. Regresi dipilih karena variabel target kita berupa angka kontinu, yaitu harga minyak per hari.
Linear Regression digunakan ketika hubungan antara fitur dan target cenderung linier. Sebaliknya, Random Forest Regressor cocok untuk pola data kompleks dan non-linier.
Sebelum memulai pelatihan, penting untuk memisahkan data menjadi data pelatihan dan pengujian untuk menghindari data leakage. Teknik ini dilakukan dengan train_test_split().
Contoh Kode: Pemisahan dan Pelatihan
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
# Fitur input dan target
X = df[['Year', 'Month']]
y = df['Price']
# Split data: 80% latih, 20% uji
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Melatih model Linear Regression
model_lr = LinearRegression()
model_lr.fit(X_train, y_train)
# Melatih model Random Forest
model_rf = RandomForestRegressor(random_state=42)
model_rf.fit(X_train, y_train)Latihan Teknis
- Tambahkan fitur baru:
DayOfWeek = df.index.dayofweek. UbahXmenjadi["Year", "Month", "DayOfWeek"]. - Gunakan
from sklearn.metrics import r2_scoredan tampilkan skor R2 pada data uji dari kedua model. - Ubah
test_sizemenjadi 0.3 dan bandingkan akurasi. - Buat grafik:
plt.scatter(y_test, y_pred)untuk melihat kecocokan prediksi dengan nilai aktual.
Dokumentasi Referensi: Linear Regression, Random Forest
Model Validation
Validasi model bertujuan untuk mengevaluasi seberapa baik model memprediksi data yang belum pernah dilihat sebelumnya. Dua metrik umum untuk regresi adalah:
- R² (R-squared): Mengukur proporsi variansi target yang dapat dijelaskan oleh fitur. Nilai mendekati 1 berarti model sangat baik.
- Mean Squared Error (MSE): Rata-rata kuadrat dari error antara prediksi dan nilai asli. Nilai lebih kecil lebih baik.
Referensi mendalam tentang metrik evaluasi regresi: Mastering Regression Evaluation Metrics
Contoh Kode Evaluasi
from sklearn.metrics import mean_squared_error, r2_score
# Prediksi menggunakan data uji
pred_lr = model_lr.predict(X_test)
pred_rf = model_rf.predict(X_test)
# Evaluasi Linear Regression
print("Linear Regression")
print("R2 Score:", r2_score(y_test, pred_lr))
print("MSE:", mean_squared_error(y_test, pred_lr))
# Evaluasi Random Forest
print("Random Forest")
print("R2 Score:", r2_score(y_test, pred_rf))
print("MSE:", mean_squared_error(y_test, pred_rf))Visualisasi Hasil Prediksi
Gunakan matplotlib untuk membandingkan nilai prediksi dan aktual:
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.scatter(y_test, pred_rf, alpha=0.5, label='Random Forest')
plt.scatter(y_test, pred_lr, alpha=0.5, label='Linear Regression', color='orange')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel("Nilai Aktual")
plt.ylabel("Prediksi")
plt.title("Perbandingan Prediksi vs Aktual")
plt.legend()
plt.grid(True)
plt.show()Penjelasan Tambahan
- R2 Score = 1 artinya model menjelaskan 100% variasi dari data target. Jika negatif, model sangat buruk.
- MSE sensitif terhadap outlier karena kuadrat dari error diperhitungkan. Cocok saat outlier perlu diperhatikan.
- MAE (Mean Absolute Error) lebih robust terhadap outlier dibanding MSE.
- Visualisasi seperti
scatter plotmembantu melihat seberapa dekat prediksi dengan nilai aktual.
Latihan Teknis
- Hitung
mean_absolute_errormenggunakanfrom sklearn.metrics import mean_absolute_error. - Ubah model regresi menjadi
DecisionTreeRegressordan bandingkan akurasi. - Gunakan
plt.hist()untuk melihat distribusi error dari salah satu model. - Ubah rasio
train_test_splitmenjadi 0.5 dan amati perubahan skor R².
Dokumentasi Referensi: Evaluasi Model Sklearn
Tuning & Finalize
Pada tahap ini, kita melakukan penyempurnaan terhadap model dengan memilih parameter terbaik (hyperparameter tuning) dan menyimpannya agar bisa digunakan kembali.
1. Apa itu Hyperparameter?
Hyperparameter adalah parameter yang ditentukan sebelum proses training, seperti n_estimators dan max_depth pada Random Forest. Penentuan nilai ini sangat mempengaruhi akurasi dan performa model.
2. Cara Menentukan Parameter
Beberapa pendekatan yang bisa digunakan:
- Trial & Error: Menentukan nilai manual dan uji performa.
- Grid Search: Mencoba semua kombinasi nilai yang ditentukan dalam grid.
- Random Search: Mencoba kombinasi acak untuk efisiensi waktu.
Contoh: Tuning Random Forest dengan GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 5, 10],
'min_samples_split': [2, 5]
}
gs = GridSearchCV(RandomForestRegressor(), param_grid, cv=5)
gs.fit(X_train, y_train)
print("Best Params:", gs.best_params_)3. Menyimpan Model
Setelah mendapatkan model terbaik, kita bisa menyimpannya dengan joblib:
import joblib
joblib.dump(gs.best_estimator_, "model_rf_best.pkl")4. Memuat dan Menggunakan Kembali Model
model_loaded = joblib.load("model_rf_best.pkl")
prediksi = model_loaded.predict(X_test)Latihan Teknis
- Modifikasi
param_griduntuk mencoba parametermin_samples_leaf. - Simpan model Linear Regression ke dalam file joblib.
- Gunakan model yang disimpan untuk memprediksi nilai baru dan bandingkan akurasinya.
Referensi: Dokumentasi GridSearchCV | Penyimpanan Model Sklearn
Referensi & Dokumentasi
- Pandas Documentation – manipulasi data dan analisis struktur tabel.
- Matplotlib Guide – visualisasi grafik dan data plotting.
- Seaborn Documentation – grafik statistik berbasis matplotlib.
- Scikit-learn Reference – dokumentasi lengkap untuk model ML.
- Joblib Documentation – penyimpanan dan pemanggilan model.
- Oil Prices Dataset (GitHub) – sumber data harga minyak mentah harian.
- NumPy Documentation – operasi matematis pada array dan numeric tools.